OurCS
Retrospective

OurCS participants for 2013.
On October 18th, I spent the weekend leading a team of 4 undergraduate women in an exploration of distributed systems for collaboration. OurCS, which stands for Opportunities for Undergraduate Research in Computer Science, held a workshop at CMU with organizers also from the University of Pittsburgh where researchers from many areas in or around computer science led a team of undergraduate women in order to exhibit the wide variety of topics one could study in this field. I was invited along with a dozen other researchers to lead a team through a tough technology problem.
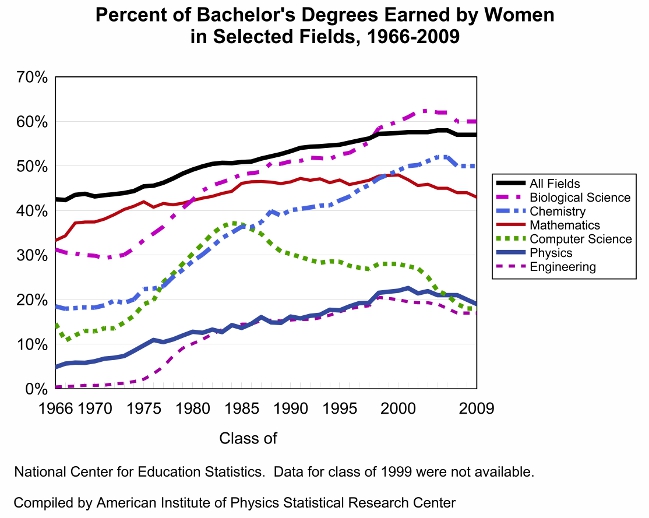
Computer Science suffers from a declining gender inclusivity.
The motivation for the event is one that I would hope is rather well-known by now. If you aren't aware, however, the computer science field, and the tech industry at large, has a critical problem with diversity. There is an insurmountable amount of evidence, but for this discussion, I'll just point to the STEM field degree trends. Computer Science is the only STEM (That is, Science-Technology-Engineering-Mathematics) field with a dramatically negative trend in the gender ratio of the degrees awarded. This workshop is an example of one small event, that must be combined with many others, that serves as a possible solution to this incredible social problem.
Speakers
The OurCS workshop combined both the active research and interactive component already alluded to, and also invited speakers to talk about their research or their roles in industry during scheduled downtime. There was a careful mix of industry, faculty, and graduate student speakers all giving their own perspective to being a woman in their respective areas.
It’s a great experience for meeting other women in the field, as well as seeing the research they’re currently involved in -- for inspiration.
— OurCS Participant
Although many of the research leaders mentioned that they wished they had more time in their groups, the speakers were still a necessary and important part of the workshop experience. These perspectives help to remove the stigma from the field causing non-men to reconsider computer science. Research has shown that much of both the disinterest and even the negative performance of those underrepresented in the field can be rooted to the development of these stereotypes. For a quick video about one particular study, I recommend Sapna Cheryan's talk about her work.
Projects
I, for one, was most impressed (beyond the ability of the students) with the diversity of the projects available at the workshop: everything from building web applications to analyzing ssl attacks to recognizing different patterns of drums in a track of music to developing technology for accessibility. The students were given the list of projects and leaders ahead of time and were able to choose which project they wished to work on. Groups of 4 to 5 were then assigned to each of the 13 projects.
Students then spent several 2-hour periods during the workshop with their research leaders discussing and developing the project. This workshop promotes a teacher/student ratio that one could never achieve in a typical classroom setting. In this case, 1 to 5 or 2 to 5, depending on the number of project leaders in the group. This allows a greater interactivity to the women participating, which will hopefully offset the typical effect of a large classroom setting of the impostor syndrome. This negative effect is commonly seen in computer science classrooms where a large number of male students participating may create doubt in women that they belong or are as capable. Inheriting the benefit from other women-only spaces, the workshop setting suggests the truth: women are very capable, they do belong, and they belong just as much in the typical classroom they will go back to.
Fantastic experience! This workshop revitalized my interest in Computer Science...
— OurCS Participant
At the end of the workshop, every student gives a small presentation as part of their team to all participants and leaders about the work they accomplished over the weekend. No team leaders are involved in the presentations, only the students. Just like any classroom setting, it is their work and they receive all accolades. They were able to portray the intent and direction of their work and, in some cases (particularly a controversial webapp), had to actively defend it against critical questioning.
I very much recommend having more such events. They inspire and promote leadership and education. The more diverse graduate students we can inspire, the more diverse our teachers will become, and thus the more diverse our field overall. If you would like to talk to the organizers of OurCS, Carol Frieze is the current chair for the event and wants to spawn more workshops across the world. I'll now devote the rest of this article to my first-hand experience as a team leader.
Perspective
For my part, I (along with Daniel Mosse, Chair of Computer Science at U. Pitt) led a group of four (Rachel, Deeksha, Grishma, and Lucy) in a design of a new form of code sharing infrastructure to rival that of GitHub. I had the idea and most of the infrastructure written before the workshop so as to lead immediately to discussion. With a distributed system, much of the design is to fix the leaks in the dam, so to speak. That is, there is no such thing as a perfect system— you are most concerned with preventing the system from failing.
Therefore, the first two parts of the workshop were about distributed systems in general. We discussed the role and motivation of distributed systems over centralized ones and gave an example of each. Afterward, I posed a real-world example of a system that could be implemented either way (bus card scanners for public transportation) and the students were quick to apply their newfound skills in designing a system and criticizing its flaws or finding and then mitigating malicious attacks.
From there, I proposed the code sharing design. It is worth explaining a little bit. The motivation stems from this article which calls for a reduction of abstractions. The design of the systems comes from another article and this talk.

Thinking about distributed systems through implementation
Essentially, it is the reduction of code into as small of pieces as you can imagine. Each useful piece of code is given an interface (name, description of how to invoke, think function definition). Relationships among interfaces can be thought of as an object-oriented network, however in this system, a single entity does not know of the entire object-oriented graph. A single interface can be passed among many nodes in the system to be discovered. When a system knows of a name for a piece of code (let's say sort for example) it is now aware that there is some code to invoke that behavior, but it does not know how to do it. So it will ask for an implementation of that interface. This is some code that will perform the behavior implied by its name. Now, whenever sort is invoked, it will compute the result with that implementation. Systems can then pass around or even create new implementations as they wish. Multiple implementations are a good thing.
The students were quick to point out a flaw that some implementations may do the wrong thing, whether by bugs (human-error), corruption (network-error), hardware (machine-error) or maliciousness. So, we introduced a new component to our system: the specification which describes the behaviors all implementations should be beholden to. Now any node in the system can introduce a rule, for instance "All elements in the output should be greater than or equal to the previous element" which would only allow implementations of sort that produced an ascending list. When new loopholes are found, any person can introduce a new rule.
With the full system, we could then discuss the social ramifications of this system. This is a socially distributed system, much like Twitter, facebook, or even GitHub. It relies on the fact that most people use the system because of its benefits and that most people are cooperative. There was some philosophical discussion about the motivations of people using this system that was very productive in highlighting some of the attack vectors for our system model.
At the end of the workshop, the students generally agreed that this system is a valid and practical criticism of centralized solutions to code sharing such as GitHub. Unlike GitHub, which generally funnels good ideas into a pass-fail system guided by only a very few number of rather non-diverse people, this system allows anybody to have a say on the global state of code. Any one person, regardless of their position relative to the code they are writing, can contribute a new way of doing something. That new technique can propagate through the system and improve various programs on remote systems automatically. The maintainers of projects and contributors need not communicate directly, but do end up collaborating more often.
Experiment
To investigate this system, we simply used it! With the proof of concept protocol implemented, I had each student play the role of a node in the system. They would each find some data they wished to visualize as a graph. They had their pick from several open data registries, such as the NYC Open Data project. You can see the code and instructions they used here.
Essentially, there was an interface for plotting, found here in ruby. They were responsible for implementing that interface using gnuplot. My own implementation can be found here. They were eventually going to teach each other their implementations through the protocol. I had a program running on a server that would take each set of data and each plot implementation and draw a graph for each permutation as it discovered new implementations.
After they were finished, they used a program that implemented the protocol. This was actually the same code running on all machines, including the server I had running the plotter. We looked at how it was implemented and showed the sharing that the system was capable of by downloading the implementations of their fellow students. In the end, we could look at the eventual plots.

After their presentation: Rachel, Grishma, Deeksha, and Lucy.
The students were very active in their discussion of the protocol and the system and quickly identified faults and possible problems. They were all pivotal in pushing the idea further and have greatly influenced any further work I may do in this space. It just goes to show that nobody should ever underestimate any student and that this workshop can and does promote confidence and the understanding to every student that they do belong and their opinions and thoughts are valuable. Such a great experience.
For instance, the students independently determined that this system could use a distributed reputation system to mitigate actively malicious implementations and specifications. They have in fact added to the entire discourse of distributed systems in only a matter of hours!
So, to conclude, let's look at the result. The following five images (a subset chosen from the many permutations) show each of the students (and my original plotter) plot implementations working on Grishma's dataset. As you can see, Grishma's original plot is at the top and it is drastically different from the other students. However, by allowing for this type of collaborative code sharing system, she can now see other ideas and be inspired by other techniques. For instance, the bottom chart, which shows a stacked bar graph, may better represent her data. This demonstrates that the system can indeed allow collaboration without explicit human arbitration, and that this is valuable. Now, we can go on to producing a larger system that will extend this idea to all code!
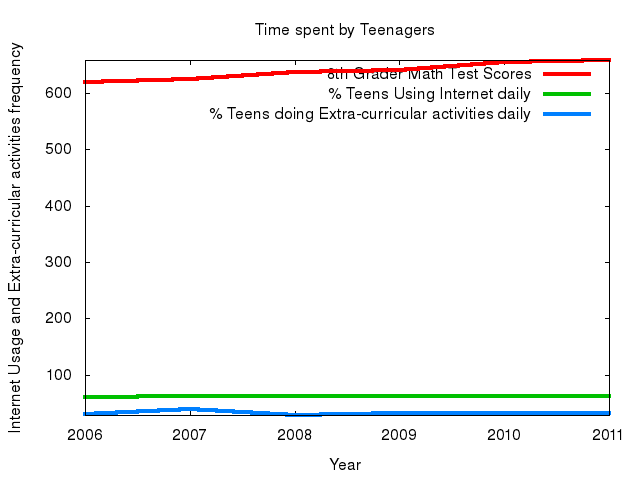
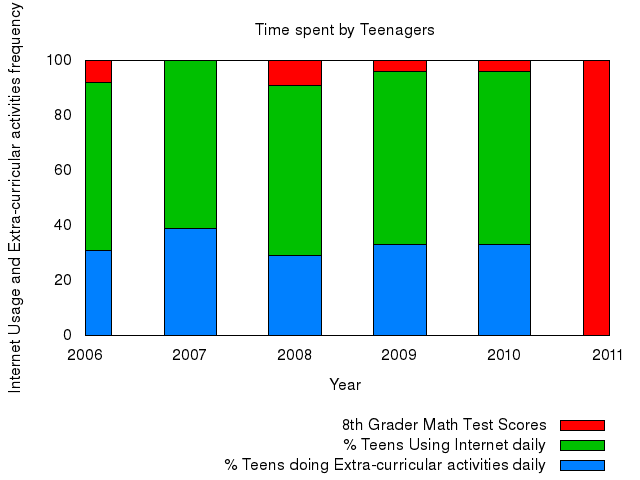
Comments
If you'd like to comment, just send me an email at wilkie@xomb.org or on either Twitter or via my Mastodon profile. I would love to hear from you! Any opinions, criticism, etc are welcome.
Donations
If you'd like to make a donation, I don't know what is best for that. Let me know.
Copyright
All content off of this domain, unless otherwise noted or linked from a different domain, is licensed as CC0